Platform overview
Twelve Labs Video Understanding Platform, currently in beta, offers an API suite for integrating a state-of-the-art (“SOTA”) foundation model that understands contextual information from your videos, making it accessible to your applications. The API is organized around REST and is compatible with most programming languages. You can also use Postman or other REST clients to send requests and view responses.
Architecture overview
The following diagram illustrates the architecture of the Twelve Labs Video Understanding Platform and how different parts interact:
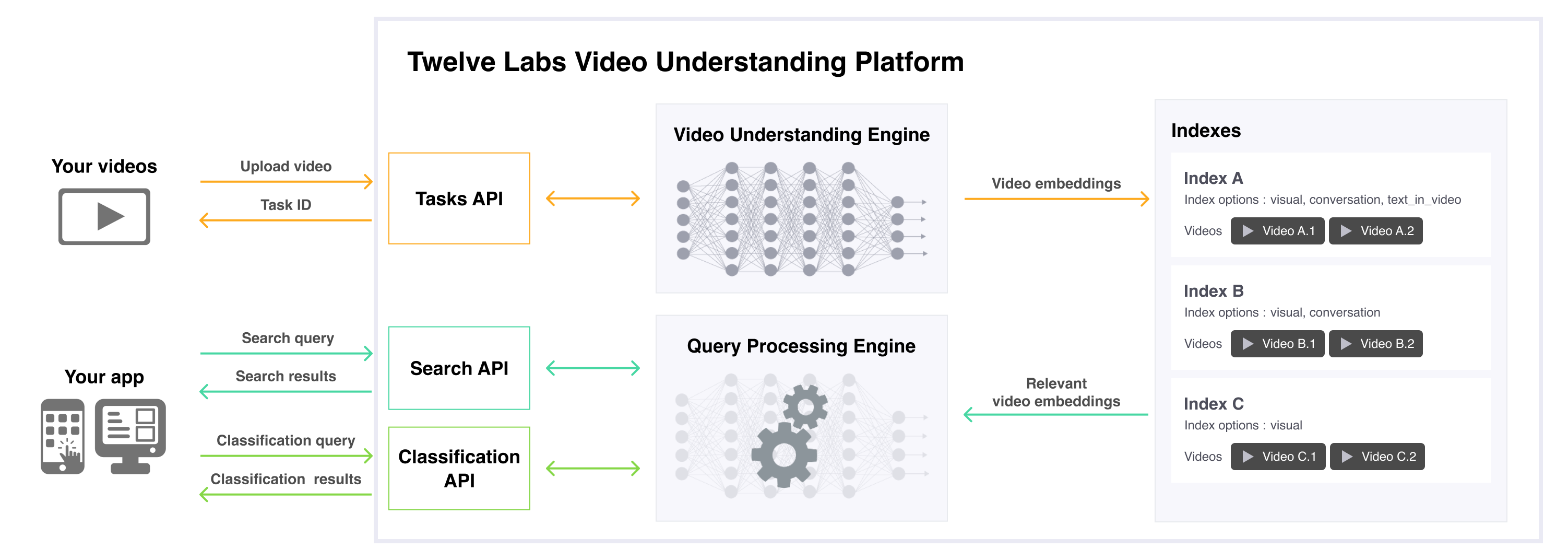
Indexes
An index is a basic unit to organize and store your video data (video embeddings and metadata) to facilitate information retrieval and processing.
Video Understanding Engines
A video understanding engine consists of a family of deep neural networks built on top of our multimodal foundation model for video understanding. The platform uses an engine to process your videos and create video embeddings, so that your video data becomes available for downstream tasks such as search or classification. For more details, see the Video understanding engines page.
Query Processing Engine
The model processes queries, such as search terms or classification prompts, into text embeddings and finds the relevant video embeddings based on how similar the embeddings are. This component returns classification or search results to your application.
Indexing options
Indexing options indicate which types of information within the video will be processed by the video understanding engine. Twelve Labs currently offers the following indexing options: visual, conversation, text_in_video, andlogo. For more details, see the Indexing options page.
Updated over 1 year ago