Video understanding engine
Twelve Labs' video understanding engine consists of a family of deep neural networks built on our multimodal foundation model for video understanding. It processes videos and creates multimodal embeddings that you can use for several downstream tasks, such as search using natural language queries and zero-shot classification. For details on performing search or classification requests, see the Search and Classify sections.
Videos contain multiple types of information, including visuals, sounds, spoken words, and texts. The human brain combines all types of information and their relations with each other to comprehend the overall meaning of a scene. For example, you're watching a video of a person jumping and clapping, both visual cues, but the sound is muted. You might realize they're happy, but you can't understand why they're happy without the sound. However, if the sound is unmuted, you could realize they're cheering for a soccer team that scored a goal.
Thus, an application that analyzes a single type of information can't provide a comprehensive understanding of a video. Twelve Labs' video understanding engine, however, analyzes and combines information from all the modalities to accurately interpret the meaning of a video holistically, similar to how humans watch, listen, and read simultaneously to understand videos.
Our video understanding engine has the ability to identify, analyze, and interpret a variety of elements, including but not limited to the following:
| Element | Modality | Example |
|---|---|---|
| People, including famous individuals | Visual | Michael Jordan, Steve Jobs |
| Actions | Visual | Running, dancing, kickboxing |
| Objects | Visual | Cars, computers, stadiums |
| Animals or pets | Visual | Monkeys, cats, horses |
| Nature | Visual | Mountains, lakes, forests |
| Sounds (excluding human speech) | Visual | Chirping (birds), applause, fireworks popping or exploding |
| Human speech | Conversation | "Good morning. How may I help you?" |
| Text displayed on the screen (OCR) | Text in video | License plates, handwritten words, number on a player's jersey |
| Brand logos | Logo | Nike, Starbucks, Mercedes |
Examples
The screenshots in this section are from the Playground. However, the principles demonstrated are similar when invoking the API programmatically.
Steve Jobs introducing the iPhone
In the example screenshot below, the query was "How did Steve Jobs introduce the iPhone?". The video understanding engine used information found in the visual and conversation modalities to perform the following tasks:
- Visual recognition of a famous person (Steve Jobs)
- Joint speech and visual recognition to semantically search for the moment when Steve Jobs introduced the iPhone. Note that semantic search finds information based on the intended meaning of the query rather than the literal words you used, meaning that the platform identified the matching video fragments even if Steve Jobs didn't explicitly say the words in the query.

To see this example in the Playground, ensure you're logged in, and then open this URL in your browser.
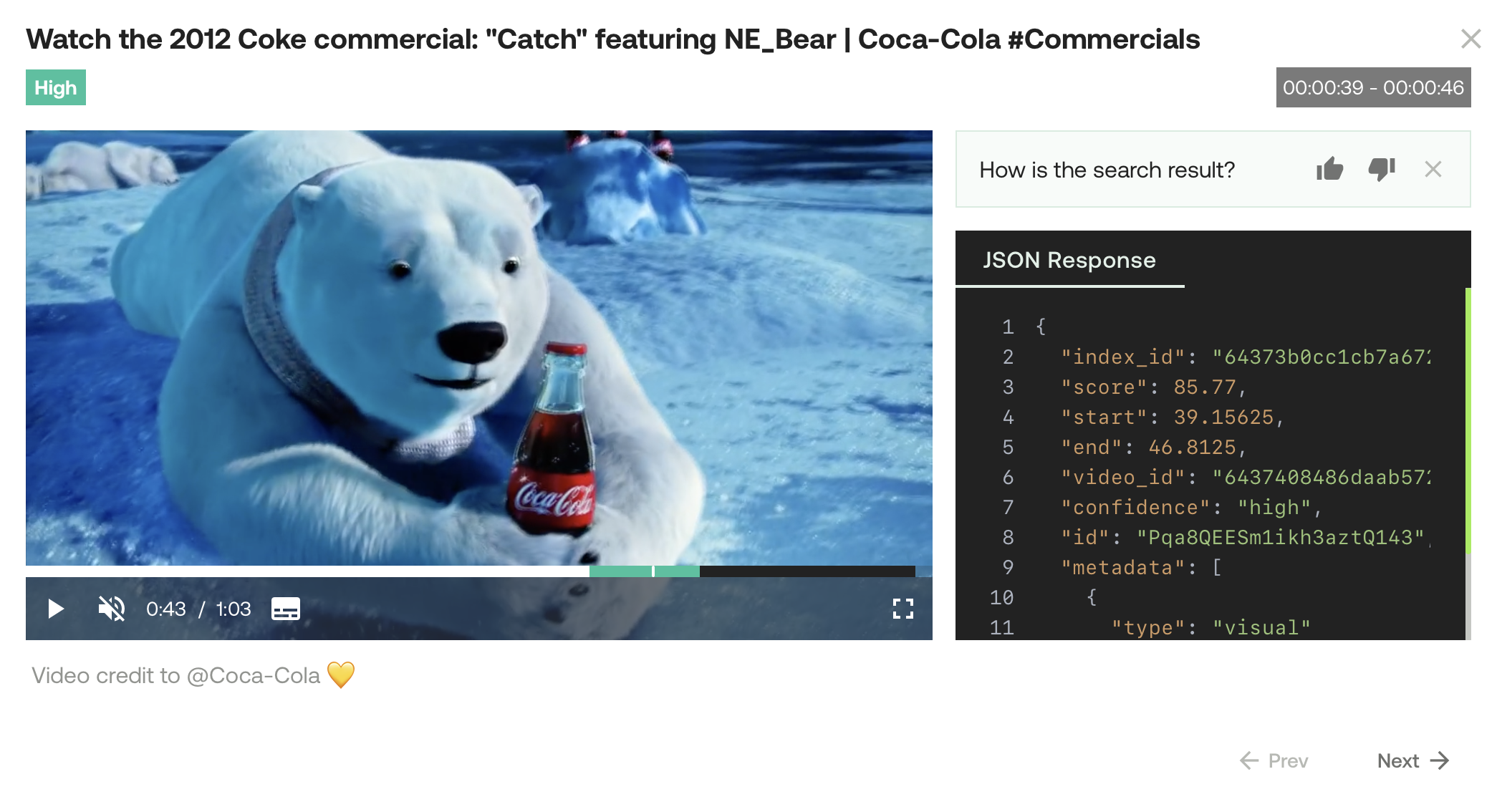
Polar bear holding a Coca-Cola bottle
In the example screenshot below, the query was "Polar bear holding a Coca-Cola bottle." The Marengo video understanding engine used information found in the visual and logo modalities to perform the following tasks:
- Recognition of a cartoon character (polar bear)
- Identification of an object (bottle)
- Detection of a specific brand logo (Coca-Cola)
- Identification of an action (polar bear holding a bottle)
To see this example in the Playground, ensure you're logged in, and then open this URL in your browser.
Engines
Twelve Labs has developed the engines described in the table below:
| Name | Description |
|---|---|
| Marengo2.5 | The latest and best-performing multimodal video understanding engine. |
| Marengo2 | This model introduced significant performance improvements. |
| Marengo | This version was available when the platform launched and enabled multimodal video understanding. However, Twelve Labs no longer offers support for this model. |
Note
Twelve Labs strongly recommends you use Marengo 2.5 for best performance. See the Pricing page for more information.
Updated 10 months ago