Platform overview
The TwelveLabs Video Understanding Platform equips developers with the following key capabilities:
- Deep semantic search: Find the exact moment you need within your videos using natural language queries instead of tags or metadata.
- Dynamic video-to-text generation: Capture the essence of your videos into concise summaries or custom reports. Additionally, you can provide a prompt detailing the content and desired output format, such as a police report, to tailor the results to your needs.
- Intuitive integration: Embed a state-of-the-art multimodal foundation model for video understanding into your application in just a few API calls.
- Rapid result retrieval: Receive your results within seconds.
- Scalability: Our cloud-native distributed infrastructure seamlessly processes thousands of concurrent requests.
TwelveLabs’ Advantages
The table below provides a basic comparison between TwelveLabs Video Understanding Platform and other video AI solutions:
- Simplified API integration: Perform a rich set of video understanding tasks with just a few API calls. This allows you to focus on building your application rather than aggregating data from separate image and speech APIs or managing multiple data sources.
- Natural language use: Tap into the model’s capabilities using everyday language to write queries or prompts. This method is more effective, intuitive, flexible, and accurate than using solely rules, tags, or keywords.
- Image-to-video search: Perform searches using images as queries and find videos semantically similar to the provided images. This addresses the challenges you face when the existing reverse image search tools yield inconsistent results or when describing the desired results using text is challenging.
- Multimodal approach: The platform adopts a video-first, multimodal approach, surpassing traditional unimodal models that depend exclusively on text or images, providing a comprehensive understanding of your videos.
- One-time video indexing for multiple tasks: Index your videos once and create contextual video embeddings that encapsulate semantics for scaling and repurposing, allowing you to search your videos swiftly.
- Flexible deployment: The platform can adapt to varied business needs, with deployment options spanning on-premise, hybrid, or cloud-based environments.
- Fine-tuning capabilities: Though our state-of-the-art foundation model for video understanding already yields highly accurate results, we can provide fine-tuning capabilities to help you get more out of the models and achieve better results with only a few examples.
For details on fine-tuning the models or different deployment options, please contact us at sales@twelvelabs.io.
Architecture
The following diagram illustrates the architecture of the TwelveLabs Video Understanding Platform and how different parts interact:
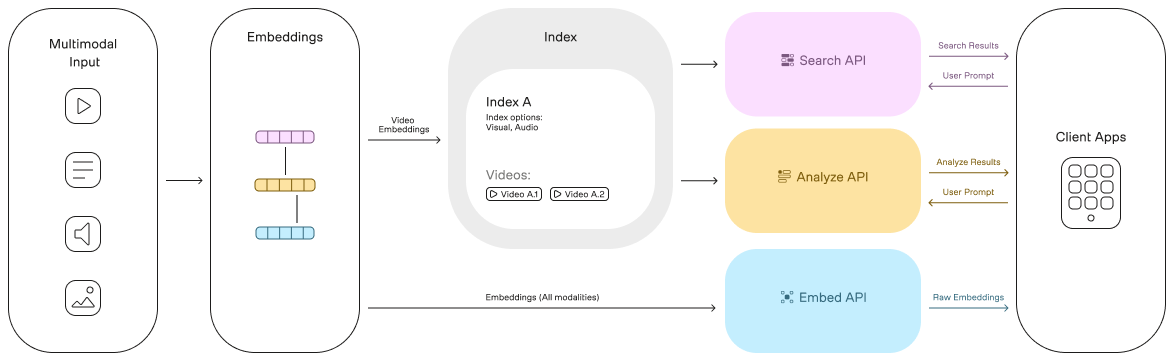
Indexes
An index is a basic unit for organizing and storing video data consisting of video embeddings and metadata. Indexes facilitate information retrieval and processing.
Video understanding models
A video understanding model consists of a family of deep neural networks built on top of our multimodal foundation model for video understanding, offering search and summarization capabilities. For each index, you must configure the models you want to enable. See the Video understanding models page for more details about the available models and their capabilities.
Model options
The model options define the modalities that a specific model will process. Currently, the platform provides the following model options: visual and audio. For more details, see the Model options page.
Query/Prompt Processing Engine
This component processes the following user inputs and returns the corresponding results to your application:
- Search queries
- Prompts for analyzing videos and generating text based on their content