Multimodal large language models
When you watch a movie, you typically use multiple senses to experience it. For example, you use your eyes to see the actors and objects on the screen and your ears to hear the dialogue and sounds. Using only one sense, you would miss essential details like body language or conversation. Furthermore, your brain processes how the visual and audio elements change over time, understanding the temporal relationship between frames to grasp the complete story. For example, you’re watching a scene where a person appears to cry. If viewed in isolation, you might conclude the person is sad. However, these tears come after a sequence showing the character winning a hard-earned award. In this case, the interpretation changes: the tears are joy, not sorrow. This illustrates how the temporal aspect — the context and sequence of events leading up to the tears — is essential for correctly determining the character’s emotions.
Using only one sense or just a static image, you would miss essential details like the evolution of emotions or the context of a situation. This is similar to how most language models operate - they are usually trained to understand either text, human speech, or separate images. Still, they cannot integrate multiple forms of information and understand the relationship between the visual and audio elements over time.
When a language model processes a form of information, such as a text, it generates a compact numerical representation that defines the meaning of that specific input. These numerical representations are named unimodal embeddings and take the form of real-valued vectors in a multi-dimensional space. They allow computers to perform various downstream tasks such as translation, question answering, or classification.

In contrast, when a multimodal large language model processes a video, it captures and analyzes all the subtle cues and interactions between different modalities, including the visual expressions, body language, spoken words, and the overall context of the video. This allows the model to comprehensively understand the video and generate a multimodal embedding that represents all modalities and how they relate to one another over time. Once multimodal embeddings are created, you can use them for various downstream tasks such as visual question answering, classification, or sentiment analysis.
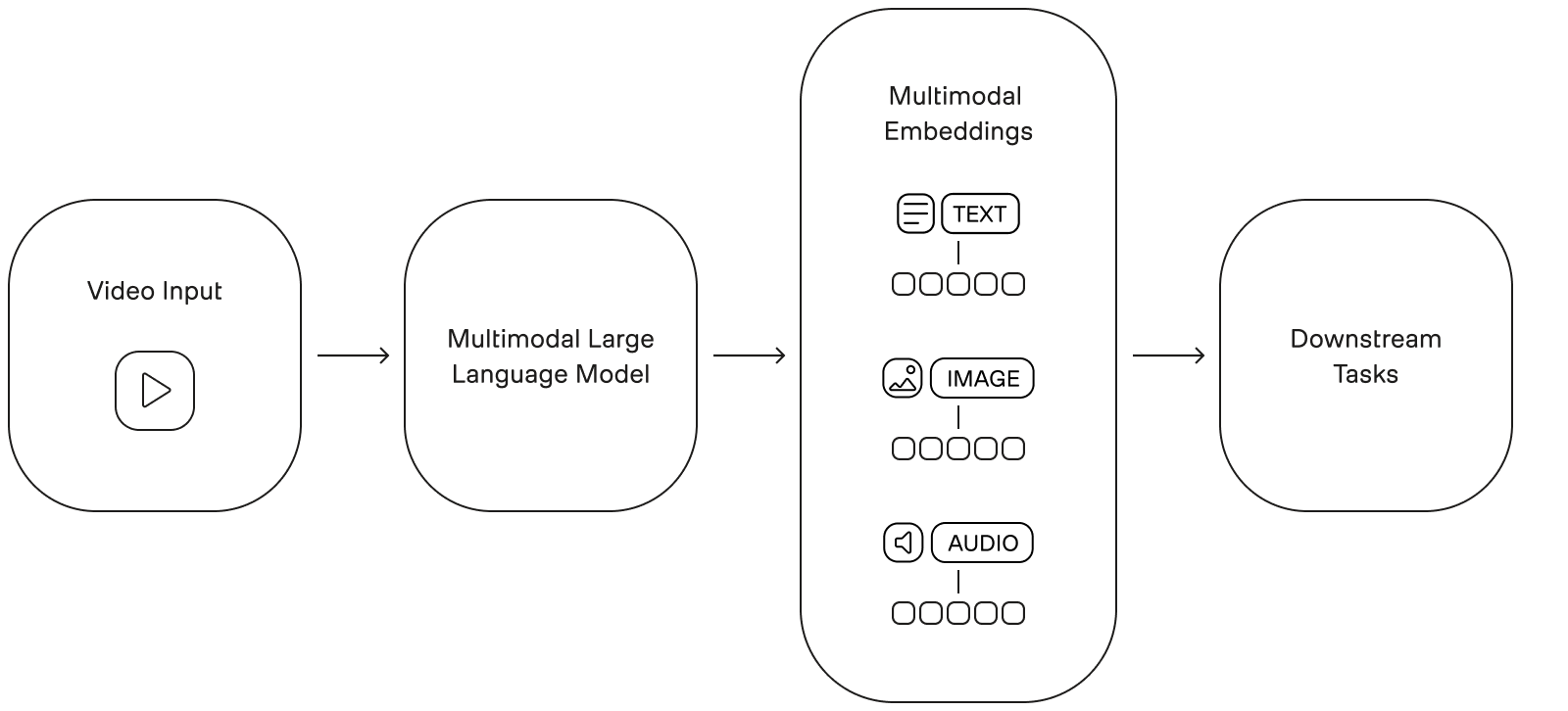
TwelveLabs’ multimodal large language models
TwelveLabs has developed two distinct models for different downstream tasks:
-
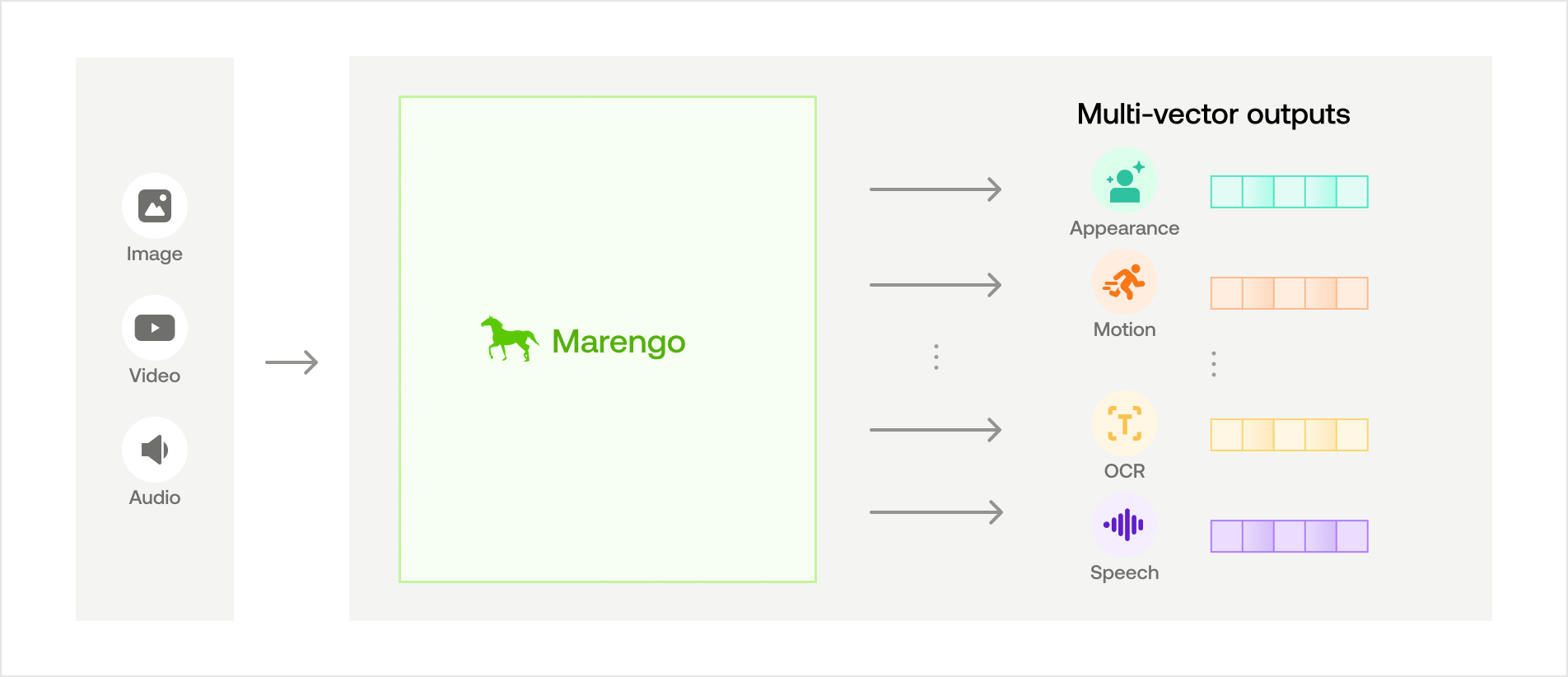
Video embedding model: This model, named Marengo, converts videos into multimodal video embeddings that enable fast and scalable task execution without storing the entire video. Marengo has been trained on a vast amount of video data, and it can recognize entities, actions, patterns, movements, objects, scenes, and other elements present in videos. By integrating information from different modalities, the model can be used for several downstream tasks, such as search using natural language queries.
Marengo uses a transformer-based architecture that processes video content through a single unified framework capable of understanding:
- Visual elements: fine-grained object detection, motion dynamics, temporal relationships, and appearance features.
- Audio elements: native speech understanding, non-verbal sound recognition, and music interpretation.
-
Video language model: This model, named Pegasus, bridges the gap between visual and textual understanding by integrating text and video data in a common embedding space. The platform uses this model for tasks that involve generating or understanding natural language in the context of video content, such as summarizing videos and answering questions.
Pegasus uses an encoder-decoder architecture optimized for comprehensive video understanding, featuring three primary components: a video encoder, a video tokenizer, and a large language model. This architecture enables sophisticated visual and textual information processing while maintaining computational efficiency.
