Backblaze B2 - Media management application
Summary: The Media Asset Management example application demonstrates how you can add video understanding capabilities to a typical media asset management application using TwelveLabs for video understanding and Backblaze B2 for cloud storage.
Description: The application allows you to upload videos and perform deep semantic searches across multiple modalities such as visual, conversation, text-in-video, and logo. The matching video segments in the response are grouped by video, and you can view details about each segment.
Code explanation: The b2-twelvelabs-example GitHub repository provides detailed instructions on setting up the example application on your computer and using it.
GitHub: Backblaze B2 + TwelveLabs Media Asset Management Example
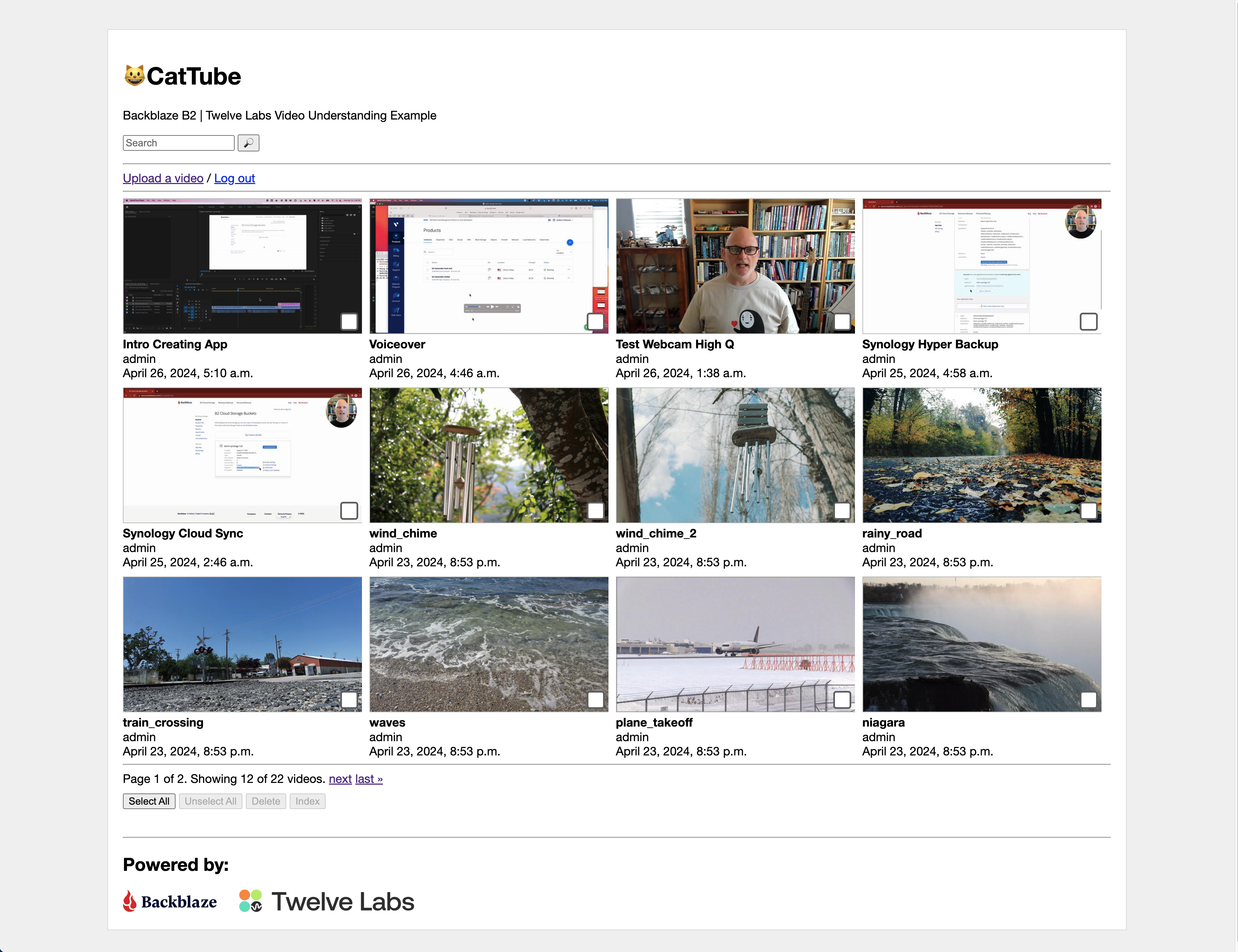
Integration with TwelveLabs
The integration with TwelveLabs video enhances the functionalities of a typical media management application by adding video understanding capabilities. The process is segmented into two main steps:
- Upload and index videos
- Search videos
Upload and index videos
A Huey task automates the process of uploading and indexing videos. For each video, the application invokes the create method of the task object with the following parameters and values:
index_id: A string representing unique identifier of the index to which the video will be updated.url: A string representing the URL of the video to be uploaded.disable_video_stream: A boolean indicating that the platform shouldn’t store the video for streaming.
Then, the application monitors the status of the upload process by invoking the retrieve method of the task object with the unique identifier of a task as a parameter:
Search videos
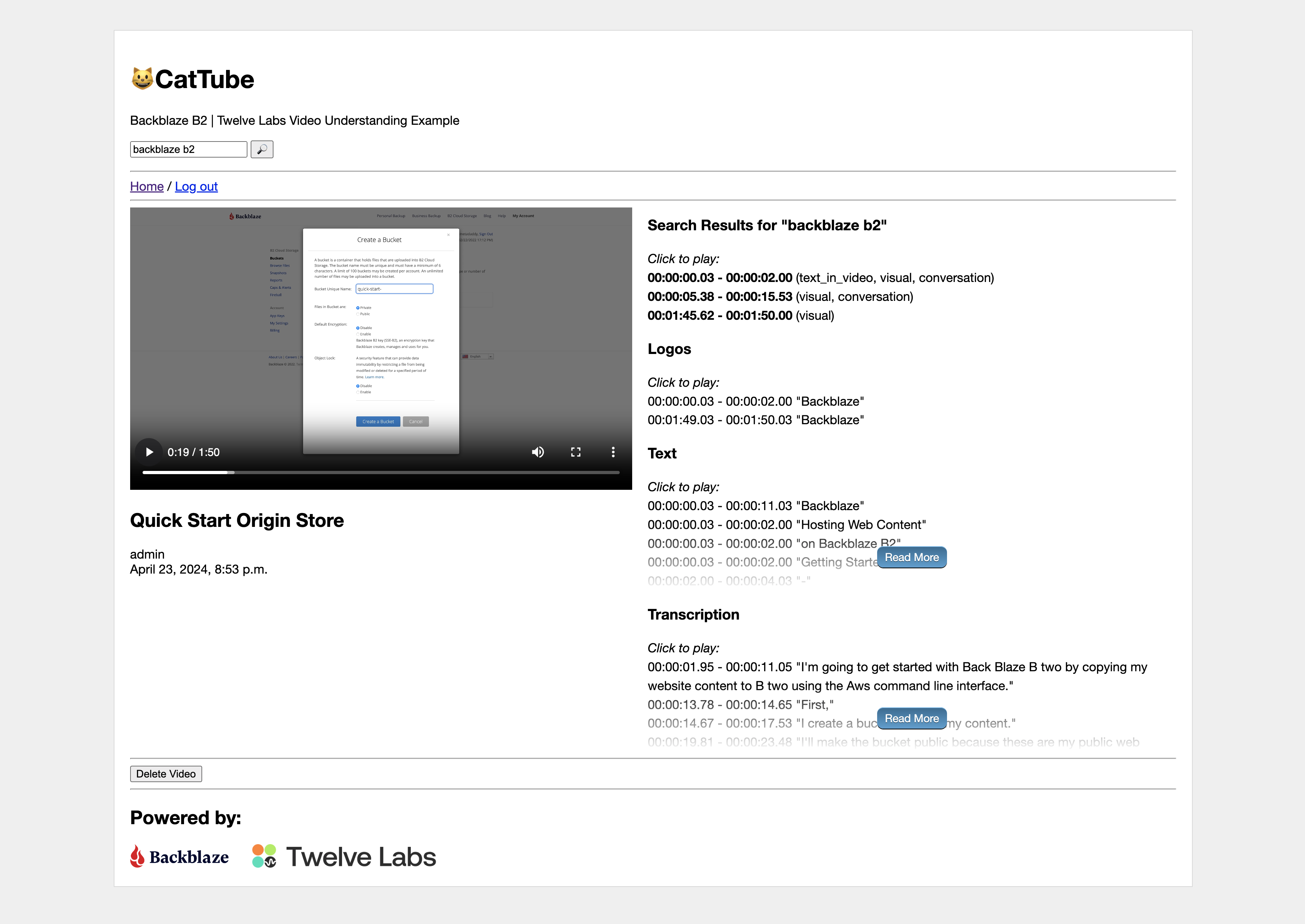
The application invokes the query method of the search object with the following parameters:
index_id: A string representing the unique identifier of the index containing the videos to be searched.query: A string representing the query the user has provided.options: An array of strings representing the sources of information the TwelveLabs video understanding platform should consider when performing the search.group_by: A string specifying that the matching video clips in the response must be grouped by video.threshold: A string specifying the sstrictness of the thresholds for assigning the high, medium, or low confidence levels to search results. See the Filter on the level of confidence section for details.
Next steps
After reading this page, you have several options:
- Customize and use the example application: Explore the Media Asset Management example application on GitHub to understand its features and implementation. You can make changes to the application and add more functionalities to suit your specific use case.
- Explore further: Try the applications built by the community or our sample applications to get more insights into the TwelveLabs Video Understanding Platform’s diverse capabilities and learn more about integrating the platform into your applications.